[Reminder] 데이터베이스 MySQL만 쓸거야?
안녕하세요. SSAFYcial 박철순입니다.
이번에는 싸피인들의 데이터베이스에 대한 견해를 넓히고자, 프로젝트 진행 시 시도해볼만한 데이터베이스를 소개하려고 합니다.
지금까지 프로젝트를 하거나 실습을 할 때 MySQL을 대부분 사용했습니다.
하지만 현재 그 외에도 Oracle, Redis, Elasticsearch, Amazon DynamoDB 등 수많은 데이터베이스 시스템이 있습니다.
저는 그 중에 사용량이 급격히 증가하고 있는 PostgreSQL과 MongoDB를 소개하겠습니다.
PostgreSQL과 MongoDB

출처: https://db-engines.com/en/ranking
DB 트렌드 랭킹을 보면
PostgreSQL과 MongoDB 의 사용량이 급격히 늘어난 것을 볼 수 있습니다.

PostgreSQL이란
오픈소스 객체-관계형 데이터베이스 시스템(ORDBMS)으로, 엔터프라이즈급 DBMS의 기능, 차세대 DBMS 기능을 제공합니다.
20여년의 오랜 역사를 가지고 있으며, 전 세계 오픈소스 개발자들과 관련 회사들이 개발에 참여하고 있습니다.
(* 객체 관계형 DB란? 복잡한 객체가 중심 역할을 합니다.)
MySQL과 PostgreSQL의 비교
우리가 흔히 사용하는 MySQL과 PostgreSQL을 비교한 표입니다.
| 항목 | PostgreSQL13 | MySQL 8 |
|---|---|---|
| 최대 DB 크기(Database Size) | 무제한 | 무제한 |
| 최대 테이블 크기(Table Size / 8KB 기준) | 32TB | 32TB |
| 최대 레코드 크기(Row Size) | 16TB | 512GB |
| 최대 컬럼크기(Field Size) | 1GB | 4GB |
| 테이블 당 최대 레크드 개수(Rows per Table) | 무제한 | 무제한 |
| 테이블당 최대 컬럼 개수(Column per Table) | 1,600 | 1,017 |
| 테이블당 최대 인덱스 개수(Indexes per Table) | 무제한 | 64 |
PostgreSQL 장점
- 비용 절감
무료이고, 오픈 소스 소프트웨어로 라이선스에 대한 비용 문제가 없다.
(BSD 라이선스(Berkeley Software Distribution 라이선스), 소프트웨어의 무료 사용, 수정 및 배포를 허용하는 오픈 소스 라이센스 입니다.) - 대량 데이터 처리
오래된 오픈소스의 안정성으로 가볍지만 대용량 처리에도 큰 문제가 없습니다.
Table Partitioning, Parallel query & multiple processes 등의 기능 지원 - 다중 버전 동시성 제어 제공(MVCC)
(* Multi-Version Concurrency Control - 동시성을 제어, 다수의 사용자 사이에서 동시에 작용하는 다중 트랜잭션의 상호간섭 작용에서 Database를 보호하는 것을 의미합니다.) - 지속적인 업데이트
많은 사용자가 있고, 점점 많아지고 있습니다. - 독창적인 자료형과 문법
표준 SQL만으로 사용할 수 있지만, PostgreSQL만의 자료형과 문법을 활용하면 더욱 효과적으로 DB를 활용할 수 있습니다.
ARRAY, JSON, RANGE 등의 자료형과, ILIKE 기능 등의 문법이 개발자들에게 큰 편의성과 효율성을 제공해줍니다.
PostgreSQL 단점
- Update 쿼리에 약하다.
UPDATE가 불안정한 문제를 가지고 있습니다. UPDATE를 반복적으로 수행하는 응용프로그램에 많은 제약을 가져옵니다. - 메모리 성능이 떨어진다.
새로운 클라이언트 연결에 대해 PostgreSQL는 새로운 프로운 프로세스 형식을 일으키고, 각각의 새로운 프로세스에 메모리가 할당되므로 많은 연결이 있는 상황에서 메모리가 빠르게 증가합니다. - 독창적인 자료형과 문법(장점이자 단점)
이러한 문법을 사용한 경우, 다른 데이터베이스 시스템으로 마이그레이션하기 쉽지 않습니다.
저는 이러한 PostgreSQL이 MySQL과 Oracle을 충분히 대체할 수 있는 관계형 데이터베이스라고 생각합니다.

MongoDB란
오픈소스 기반 비관계형 데이터베이스 관리 시스템으로 테이블 및 행 대신 유연한 문서를 활용해 다양한 데이터 형식을 처리하고 저장합니다. NoSQL 솔루션인 MongoDB는 관계형 데이터베이스 관리 시스템을 필요로 하지 않으므로, 사용자가 다변량 데이터 유형을 쉽게 저장하고 쿼리할 수 있습니다. 이는 데이터베이스 관리를 간소화하며, 뛰어난 확장성을 가진 크로스 플랫폼 애플리케이션 및 서비스 환경을 구축합니다.
NoSQL이란
비관계형 데이터베이스로, 흔히 아는 Database와 다른 쿼리, 구조를 가집니다.
not only SQL 데이터베이스를 뜻하며, SQL만을 사용하지 않는 데이터베이스로, 관계형 데이터 베이스도 저장할 수 있습니다. 높은 확장성과 가용성이 주요 장점인 NoSQL 데이터베이스는 실시간 웹 애플리케이션 및 빅 데이터에 널리 사용됩니다.
NoSQL 데이터베이스는 2000년대 말에 스토리지 비용이 크게 하락하면서 등장했습니다.
MongoDB 특징
- Document-Oriented Storage
모든 데이터가 JSON 형태로 저장되며, 스키마가 없습니다.
스키마가 없으므로, 각 필드는 서로 다른 데이터 타입을 가질 수 있고, DB에 저장된 Documents도 각 다른 다양한 필드를 가질 수 있습니다.
복잡한 구조도 쉽게 저장할 수 있습니다. - Full Index Support
다양한 인덱싱을 제공하고, 인덱싱 기능 덕분에 거의 모든 쿼리를 빠르게 처리할 수 있습니다. - 데이터 복제를 통한 가용성 향상
- Auto-Sharing
Primary key를 기반으로 여러 서버에 데이터를 나누는 Scale-Out이 가능합니다.
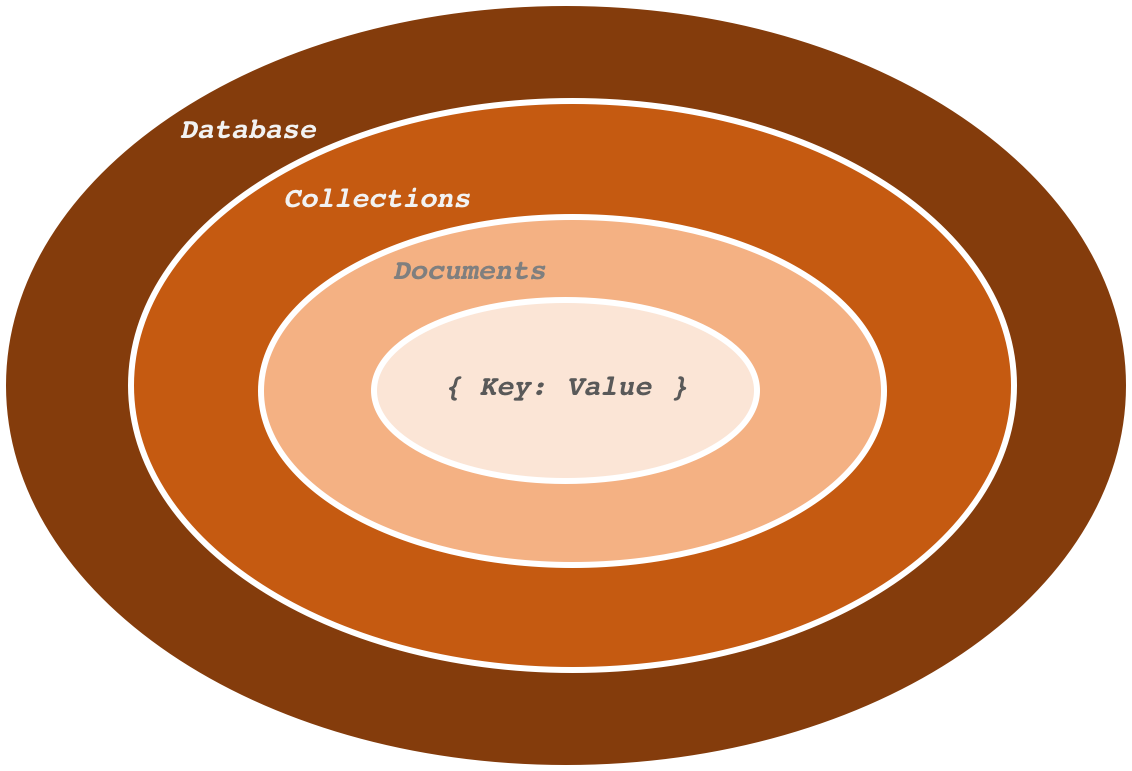
MongoDB 구조
몽고 DB의 구조는 다음과 같이 데이터베이스 > Collection > Document의 구조로 되어있습니다.
Collection은 RDB의 테이블과 비슷한 역할을 합니다.
Document는 RDB의 레코드와 비슷한 역할을 합니다.

Document?
Document 예시
{
"_id": ObjectId("5099803df3f4948bd2f98391"),
"username": "ljh",
"name": { first: "J.H.", last: "Lee" }
}MongoDB의 중요한 특징입니다. JSON 형식으로 Key:Value의 형태로 저장이 됩니다.
ID는 12바이트의 각 Document의 유일함을 제공합니다.
이러한 Field와 Value가 모여 Document 구조를 이루게 됩니다.
Document는 동적 스키마를 가지고 있기 때문에, 같은 Collection 안의 Document 끼리 다른 스키마를 갖고 있을 수 있습니다.
서로 다른 데이터들을 가지고 있습니다.
Collection?
컬렉션은 MongoDB Document의 그룹입니다. 컬렉션들은 각각 여러개의 Document를 포함합니다.
RDB의 테이블과 비슷한 개념이지만 스키마를 따로 가지지 않습니다.
MongoDB와 기존 RBDMS와의 차이점
저장 구조
| MongoDB | RDBMS(관계형데이터베이스) |
|---|---|
| 데이터베이스(Database) | 데이터베이스(Database) |
| 컬렉션(Collection) | 테이블(Table) |
| 도큐먼트(Document) | 레코드(Record) |
| 필드(Field) | 컬럼(Column) |
| 인덱스(Index) | 인덱스(Index) |
| 쿼리의 결과로 "커서(Cursor)" 반환 | 쿼리의 결과로 "레코드(Record)" 반환 |
데이터를 저장하는 관점에서는 많은 공통점이 있습니다. Collection이나 Document 와 같이 이름이 다를 뿐 비슷한 역할을 합니다.
MongoDB에서 쿼리의 결과로 커서를 반환하는 이유는 쿼리의 결과를 클라이언트 서버의 메모리에 모두 담아두지 않아도 처리할 수 있게 하기 위해서 입니다.
커서를 읽을 때마다 서버에서 도큐먼트를 가져오는 것은 아니고 필요할 때마다 지정된 페이지 사이즈 단위로 서버로부터 전송받아 MongoDB 클라이언트 서버에 캐싱한 후에 유저에게 서비스합니다.
쿼리 비교
| MongoDB | RBDMS |
|---|---|
| INSERT | |
| db.users.insert({ name: "lee", city: "seoul" }) | insert into users ("name", "city") values("lee", "seoul") |
| SELECT | |
| db.users.find({ name: "lee" }) | select * from users where name="lee" |
| UPDATE | |
| db.users.update({ name: "lee" }, { $set: { city: "busan" }}) | update users set city="busan" where name="lee" |
| DELETE | |
| db.users.remove({ name: "lee" }) | delete from users where name="lee" |
CRUD의 쿼리는 다음과 같은 차이가 있습니다.
MongoDB의 장점
- Flexibility
Schema less이기 때문에 어떤 형태의 데이터라도 쉽게 저장이 가능합니다. - Perfomance
Read & Write 성능이 뛰어납니다. - Scalability
스케일 아웃 구조, Auto sharding을 지원합니다.
(* sharding - 샤딩은 각 DB 서버에서 데이터를 분할하여 저장하는 방식입니다.) - Deep Query Ability
문서 지향적 쿼리를 사용하여 SQL만큼 강력한 Query성능을 제공합니다. - Conversion / Mapping
JSON 형태로 저장이 가능하여, 직관적이고 개발이 편리합니다.
MongoDB의 단점
- JOIN이 없습니다.
join이 필요 없도록 데이터 구조화가 필요합니다. - Memory Mapped File
파일 엔진 DB입니다. 메모리 관리를 OS에게 위임하며, 메모리에 의존적이고, 메모리 크기가 성능을 좌우합니다. - SQL을 완전히 이전할 수 없습니다.
- B트리 인덱스 사용
B트리는 크기가 커질수록 새로운 데이터를 입력하거나 삭제할 때 성능이 저하됩니다.
이런 B트리 특성 때문에 데이터를 넣어두면 변하지 않고, 정보를 조회하는데 적합합니다.
NoSQL을 통해 데이터를 쉽게 저장, 관리할 수 있는 MongoDB는 빠른 개발, 확장성을 위한 프로젝트에 적용할 수 있을거라 생각합니다!!
여러 데이터 베이스 시스템을 사용, 경험 하면서 그 선택지를 넓히는 것도 경쟁력있는 개발자로 성장하는데 큰 도움이 될 것 같습니다. 끝까지 글을 읽어주셔서 감사합니다.


[참고]